idea中使用内嵌git插件
以前使用idea中的git比较习惯,也用过source tree、小乌龟一些插件。麻烦,总要切出去切回来。也不想用命令行,对比代码revert不方便。
个人比较懒就喜欢用idea自带的git插件和一些简单git的命令。
重装系统之后,导入项目。idea中的git插件确一直不可用
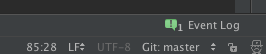
git插件不可用的状态没有git:master的显示
解决方式:正确的导入maven项目
1.选择一个项目目录,mkdir directory
2.cd directory, git init初始化一个git目录
3.在这个git目录拉取maven项目
4.重启idea
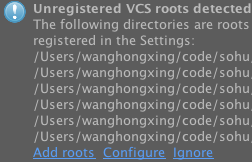
5.idea会提示unregistered vcs roots detected如图,选择add roots